TL;DR: If you run Redis on AWS, you have four real options: ElastiCache with traditional nodes, ElastiCache Serverless, MemoryDB, or self-hosted Redis OSS on EC2. They look similar from outside — Redis protocol, same client libraries — but underneath, their durability semantics, failure modes, and cost curves are very different. Pick wrong and you either lose writes on failover, pay 3× more than needed, or spend a quarter rebuilding backups and monitoring. This is Part 2 of the Redis in Production series, focused on the AWS-specific deployment decision.
Prerequisites
You should read Part 1: Redis in Production — Persistence, Replication, and HA first, or already understand RDB vs AOF, Redis Sentinel, and Redis Cluster mode. Basic AWS familiarity (VPCs, security groups, EC2 instance families) is expected. You don’t need prior hands-on experience with MemoryDB or ElastiCache Serverless.
The Problem: “Just Use ElastiCache” Is Not an Answer
Every AWS team has had this conversation. Someone asks, “How should we run Redis?” Someone else says, “Just use ElastiCache.” And that ends the discussion, until six months later, when the team realizes their ElastiCache writes occasionally disappear on failover, or their bill has quietly tripled because they provisioned r6g.2xlarge nodes for a workload that actually runs at 5% utilization.
There is no single “just use X” answer for Redis on AWS. The service names look interchangeable — they all speak Redis protocol, they all run in your VPC, they all advertise Multi-AZ, but the engines underneath have meaningfully different durability models, failure modes, and cost structures.
ElastiCache with standard nodes is the cache most teams think of. ElastiCache Serverless eliminates the instance-sizing step but charges per request. MemoryDB is a genuinely different product: a Redis-compatible database with synchronous durability. And self-hosted Redis OSS on EC2 is still the cheapest per-GB option if you actually use what you provision.
This post walks through the four paths, the decision framework, and the traps that only become visible once you’re in production. Part 1 of the series covered the engine-level concerns (RDB, AOF, eviction, Sentinel vs Cluster). This part is about where you run it on AWS.
Background: What Changed in 2023–2024
Two things reshaped the AWS Redis landscape in the last 18 months.
November 2023: ElastiCache Serverless went GA (AWS announcement). It changed the pricing model from instance-hours to a pay-per-use billing based on storage (GB-hours) plus request units called ECPUs (ElastiCache Processing Units). For workloads that don’t run hot all day, this is structurally cheaper than provisioning nodes for peak.
March 2024: Redis Inc. changed the license from BSD-3 to a dual license (RSAL + SSPLv1) for Redis 7.4 and above. Within weeks, the Linux Foundation launched Valkey, a BSD-3-licensed fork with AWS, Google Cloud, Oracle, and Ericsson on the steering committee. AWS now offers Valkey as a first-class engine on both ElastiCache and MemoryDB alongside Redis OSS.
The practical impact for AWS teams: you now have license-aware engine choices inside the same managed services. Protocol compatibility is preserved (Valkey is a fork of Redis 7.2.4, and clients that speak Redis speak Valkey), but your choice affects licensing obligations if you ever take the software in-house.
The Four Paths
Let’s define what each one actually is before comparing them.
Path 1: ElastiCache with Traditional Node-Based Clusters
This is the original managed Redis on AWS. You pick an instance type (r7g.large, r7g.xlarge, cache.m7g.large, etc.), you pick a cluster mode (enabled = sharding, disabled = single primary with replicas), and AWS handles Multi-AZ replication, backups to S3, automated patching, and auto-failover.
Under the hood, this is Redis OSS (or Valkey) with async replication. Writes to the primary are acknowledged immediately and propagate asynchronously to replicas. On primary failure, ElastiCache promotes a replica — typically in about 35 seconds for Multi-AZ with automatic failover enabled (ElastiCache failover docs). Writes that hadn’t propagated before the failure are lost.
Strengths: fast reads and writes (single-digit ms), broad Redis feature coverage (streams, pub/sub, Lua, modules like RedisJSON and RedisSearch), reserved node discounts up to 40–60% for 1-year / 3-year commitments (ElastiCache pricing).
Weaknesses: Async replication can lead to write loss during failover. You pay for the full instance 24/7, even when utilization drops.
Path 2: ElastiCache Serverless
Same engine (Redis OSS or Valkey), same protocol, but AWS manages the sizing. You get an endpoint; AWS handles capacity scaling behind it. Billing is GB-hours of stored data plus ECPUs for commands — roughly one ECPU per simple read/write, more for large payloads or complex commands.
The break-even point compared to reserved nodes lands near ~25% average utilization, though this depends heavily on your specific workload shape. At that price or lower, Serverless is cheaper. At more, reserved nodes win. Don’t use Serverless for high-throughput steady workloads — the per-ECPU premium adds up.
Strengths: no instance sizing, automatic scaling for bursts, good fit for intermittent workloads (dev/test, batch jobs, cron-driven caches).
Weaknesses: opaque scaling (you don’t see the underlying nodes), per-ECPU premium at high sustained throughput, no data tiering or module support currently, same async-replication durability model as node-based ElastiCache.
Path 3: Amazon MemoryDB
MemoryDB is often introduced as “durable Redis,” and that framing is more accurate than marketing usually is. It is not a cache, it’s a Redis-compatible primary database.
The architectural difference is the distributed transaction log. When a client writes to a MemoryDB primary node, the write is synchronously committed to a Multi-AZ distributed log before the client gets an ACK (MemoryDB developer guide). Only after the log commit does the primary apply it in memory and begin replicating to replicas. This means:
A crash of the primary does not lose acknowledged writes; the log replays them on recovery.
Failover to a replica is consistent; the replica catches up from the log before serving.
Writes incur the log commit latency of single-digit ms rather than sub-ms like ElastiCache.
Strengths: durable, Multi-AZ write semantics; Redis-compatible API; vector search (added late 2023); single-digit ms read latency.
Weaknesses: ~2–3× the per-GB cost of ElastiCache for the same memory footprint; single-region only as of April 2026 (no equivalent of Global Datastore); writes are slower than ElastiCache because of the log commit.
Path 4: Self-Hosted Redis OSS on EC2
You install Redis (or Valkey) yourself on EC2 instances, run Sentinel or Cluster, set up backups to S3, configure monitoring, and handle patching. Terraform modules exist. The Bitnami AMI is maintained. This works.
Strengths: lowest unit cost, no managed-service premium. Full control over config (custom modules, custom parameter tuning, non-standard versions). No license coupling to AWS.
Weaknesses: You are the SRE team. Patching, backups, monitoring, failover testing, VPC networking, and on-call for 3 AM node failures are all yours. The TCO math usually works out worse than ElastiCache for small teams once you account for engineer time at realistic hourly rates.
Architecture at a Glance
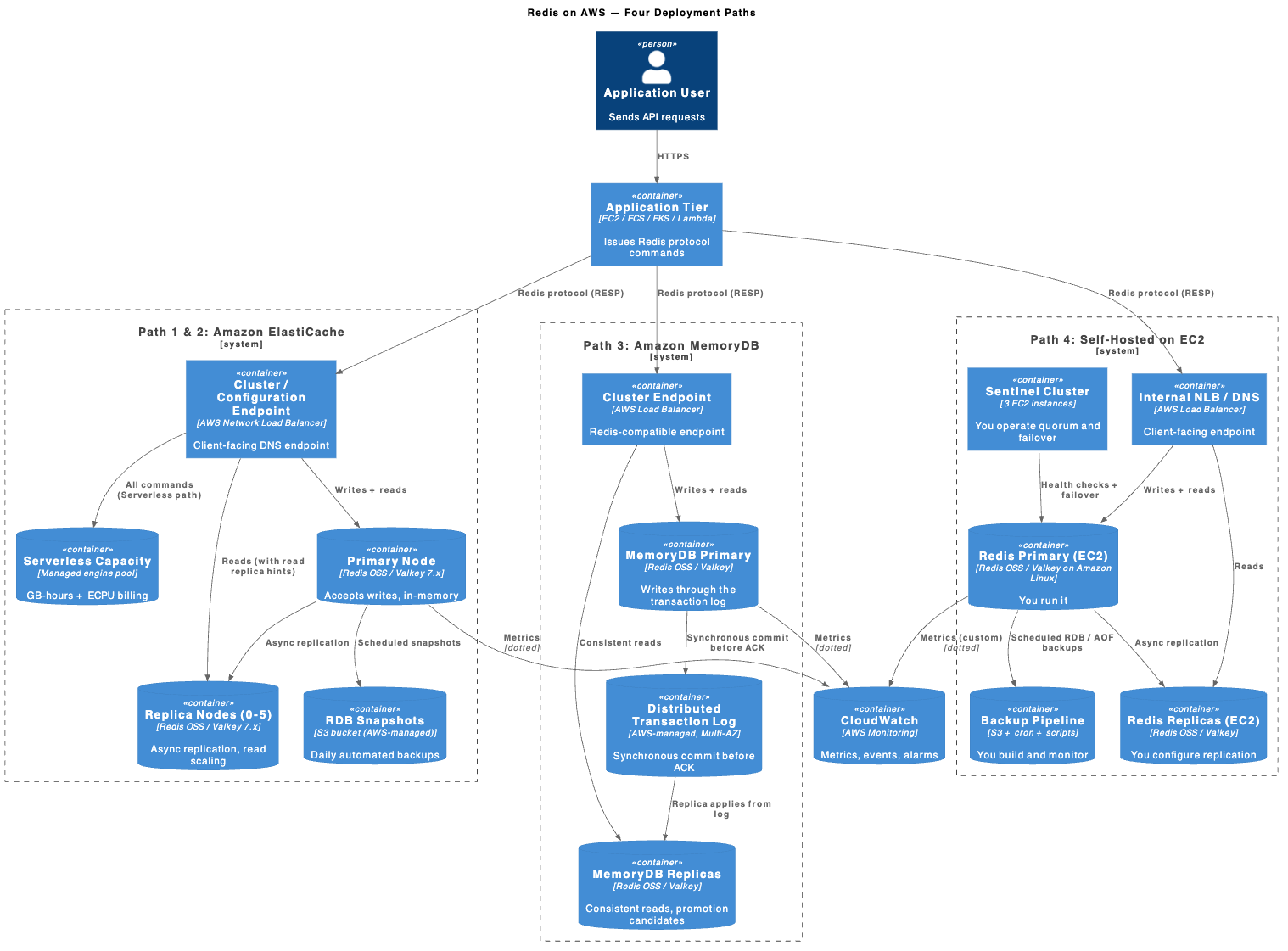
See Redis AWS C4 Container Three Paths for a side-by-side container view of all four paths, showing the control plane, data plane, and persistence layer for each.
The most important architectural distinction is persistence. ElastiCache (nodes and Serverless) has RDB snapshot backups to S3 and optional AOF, but the hot write path is async in-memory replication. MemoryDB’s hot write path goes through a durable log before the in-memory application. Self-hosted is whatever you configure.
The Cost Conversation Nobody Has Honestly
Here’s the comparison most AWS blogs skip. Let’s price out a realistic production workload: 50 GB of cache data, 10,000 commands per second at peak, 2,000 commands per second at average, running in us-east-1, with on-demand pricing for April 2026.
At this workload shape, ElastiCache with reserved nodes wins on pure dollar cost. Serverless is competitive but costs more per unit of throughput. MemoryDB costs roughly twice as much when durability is needed, and is wasteful when it isn’t. Self-hosted looks cheapest, but the engineer-hours to operate it reliably typically add $2k–$5k/month in opportunity cost for a small team.
Here, Serverless wins decisively. Paying $800/month for nodes you use 8 hours a day is a waste. Serverless bills for actual GB-hours, and ECPUs usually cost half to a third as much for this pattern.
Scenario C: Durable write store (order events, counters, sessions that can’t disappear)
Here, MemoryDB is the only right answer on this list. Using ElastiCache for genuinely durable state is a latent production incident. When a primary fails mid-write on an async-replicated ElastiCache cluster, those writes are gone. MemoryDB’s transaction log is the whole point of the product; pay the 2× cost to buy durability, or pick a different primary database entirely (DynamoDB, PostgreSQL).
Failure Modes You’ll Actually Hit
Each path fails in characteristic ways. Knowing them ahead of time saves the 3 AM diagnosis.
ElastiCache Node Replacement Blips
AWS periodically replaces cache nodes for maintenance. For Multi-AZ clusters with automatic failover, this typically causes a brief latency spike or a sub-minute connection reset as the replica promotes. Clients with poor retry logic surface this as user-visible errors. Fix: use a Redis client with connection pooling and automatic retry on CLUSTERDOWN / MOVED responses. Subscribe to ElastiCache event notifications to receive notifications when replacements occur.
ElastiCache Serverless Cold Metrics
Because Serverless abstracts the underlying nodes, you cannot SSH in or inspect per-node INFO. Your debugging surface shrinks to the CloudWatch metrics AWS exposes. If you’re used to reading Redis slowlogs for tail latency analysis, this is a degraded experience. It’s fine for most cache workloads, but painful when you need to diagnose an anomaly.
MemoryDB Write Latency Spikes Under Cross-AZ Pressure
MemoryDB’s transaction log requires a Multi-AZ commit before ACK. If one AZ has elevated network latency, the P99 latency for everyone rises. This is usually a 5-30-second blip and self-resolves, but it will show up in your dashboards in a way that never happens in ElastiCache. Don’t alert on raw P99 without a rolling window.
Self-Hosted Split-Brain During AZ Failure
A partial AZ failure is the classic Redis Sentinel nightmare: two sides of the cluster can’t see each other, each side elects its own master, writes go to both, and when the partition heals, you have to reconcile divergent state. AWS’s managed options handle this for you. Self-hosted, you own it. Write the runbook before you need it.
The License Question
If you’re starting fresh in 2026, the Valkey vs Redis OSS decision is worth thinking through once.
Redis 7.4+ is dual-licensed (RSAL + SSPLv1). These are source-available licenses, not OSI-approved open source. For most companies that just run Redis internally and don’t redistribute it, this is legally fine. For vendors who offer Redis as part of a product, it can be a problem.
Valkey 7.2 and 8.x (Valkey repo) is BSD-3 licensed under the Linux Foundation. AWS, Google Cloud, Oracle, and Ericsson contribute to it. It’s protocol-compatible with Redis 7.2.x.
On AWS, ElastiCache and MemoryDB offer both engines. If you have a strong preference for OSI-approved open source or are concerned about license drift, pick Valkey. If you need Redis 7.4+ features not yet in Valkey (the gap has been closing), pick Redis. For most teams, the choice doesn’t matter for day-one operations but matters for multi-year architectural flexibility.
For self-hosted, the choice matters more because you own the upgrade path. Teams newly self-hosting in 2026 are defaulting to Valkey.
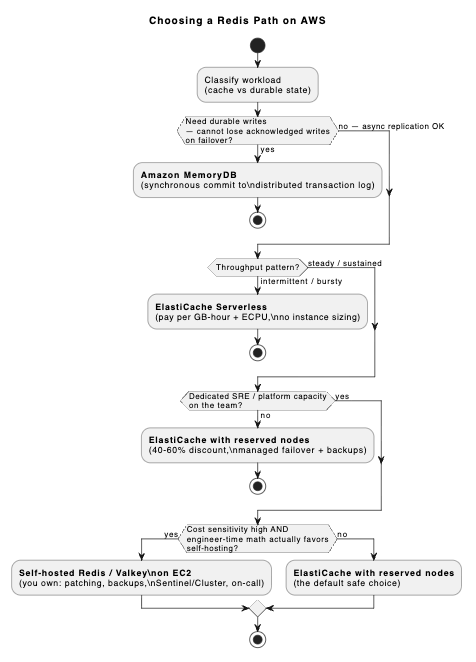
The Decision Framework
Four questions, in order. The answers produce the path.
Question 1: Do you need durable writes? Can you tolerate losing acknowledged writes during failover?
Cannot tolerate loss → MemoryDB. Stop here.
Can tolerate → continue.
Question 2: Is your throughput roughly steady, or is it intermittent/bursty?
Intermittent/bursty → ElastiCache Serverless.
Steady → continue.
Question 3: Do you have dedicated SRE / platform capacity on your team?
No → ElastiCache with reserved nodes.
Yes → continue to Q4.
Question 4: Is cost sensitivity high, and are you willing to absorb operational burden for savings?
Yes, and you’ve actually done the engineer-time math → self-hosted Redis / Valkey on EC2.
No → ElastiCache with reserved nodes.
See the Redis AWS flowchart above to choose the path through the full decision tree.
Trade-offs and When NOT to Use Each Path
Don’t use ElastiCache nodes for intermittent workloads. Paying for peak capacity 24/7 when your traffic is a 9-to-5 shape is pure waste. Serverless or scheduled scaling is the fix.
Don’t use ElastiCache Serverless for heavy sustained throughput. The ECPU premium makes it expensive above ~25% utilization. Reserved nodes win there.
Don’t use MemoryDB as a cache. It’s a durable database. You’re paying for durability you don’t need, plus slower writes. For caching, pick ElastiCache.
Don’t use self-hosted Redis OSS just to save money. Do the engineer-hour math honestly. If your platform team is already overloaded, managed is cheaper overall. Self-host only when you actually need the control, or the cost at scale crosses the threshold (typically 100+ GB datasets with full utilization).
Don’t use Redis on AWS as your primary transactional database. MemoryDB is durable enough that you could, but its query model is still key-value. For transactional SQL or complex queries, use Aurora / RDS / DynamoDB. MemoryDB is for cases where you need Redis’s data structures and access patterns with durability guarantees.
Key Takeaways
ElastiCache (nodes) is the default, low-cost, high-throughput cache. Accept the async-replication durability model, don’t use it for state you can’t afford to lose.
ElastiCache Serverless is the right answer for intermittent workloads. Don’t use it for steady high-throughput; the ECPU premium kills the economics.
MemoryDB is a durable Redis-compatible database, not a cache. Use it when write durability matters more than the ~2× cost.
Self-hosted Redis/Valkey on EC2 is cheapest per GB only if your engineer time is worth less than the managed service premium. For most teams, it isn’t.
Valkey gives you a BSD-3-licensed Redis-compatible engine across both ElastiCache and MemoryDB. Default to it for new deployments unless you need a Redis-OSS-only feature.
Cross-AZ data transfer incurs real costs at high write throughput. Budget for it before deployment.
Match the durability tier to the data’s loss cost. Don’t default to “more durable is better”. It’s more expensive and often slower.