

Introduction
Amazon Simple Storage Service (S3) stands as one of the foundational pillars of cloud computing, revolutionizing how organizations store, manage, and access data at scale. Since its launch in 2006, S3 has evolved from a simple object storage service into a comprehensive data management platform that powers everything from static websites to enterprise data lakes.
In today’s data-driven landscape, organizations generate and consume unprecedented amounts of information. Traditional storage solutions struggle with scalability, accessibility, and cost-effectiveness at cloud scale. S3 addresses these challenges by providing virtually unlimited storage capacity, global accessibility, and a pay-as-you-use pricing model that has become the gold standard for cloud storage economics.
This comprehensive guide explores every aspect of AWS S3, from fundamental concepts to advanced enterprise implementations, providing technical professionals with the knowledge needed to leverage S3 effectively in their cloud architecture strategies.
Background and Context: Understanding Object Storage
The Evolution of Data Storage
Traditional storage architectures relied heavily on block storage (direct attached storage, SAN) and file storage (NAS systems) designed for structured, hierarchical data organization. While these approaches served well in on-premises environments, they presented significant limitations in cloud-scale scenarios:
- Scalability Constraints: Traditional storage systems required manual capacity planning and hardware procurement
- Geographic Limitations: Data accessibility was restricted to local network boundaries
- Maintenance Overhead: Hardware lifecycle management, software updates, and backup procedures required significant operational investment
Object Storage Architecture
Object storage represents a paradigm shift in data management philosophy. Unlike traditional block or file storage, object storage treats each piece of data as a discrete object containing:
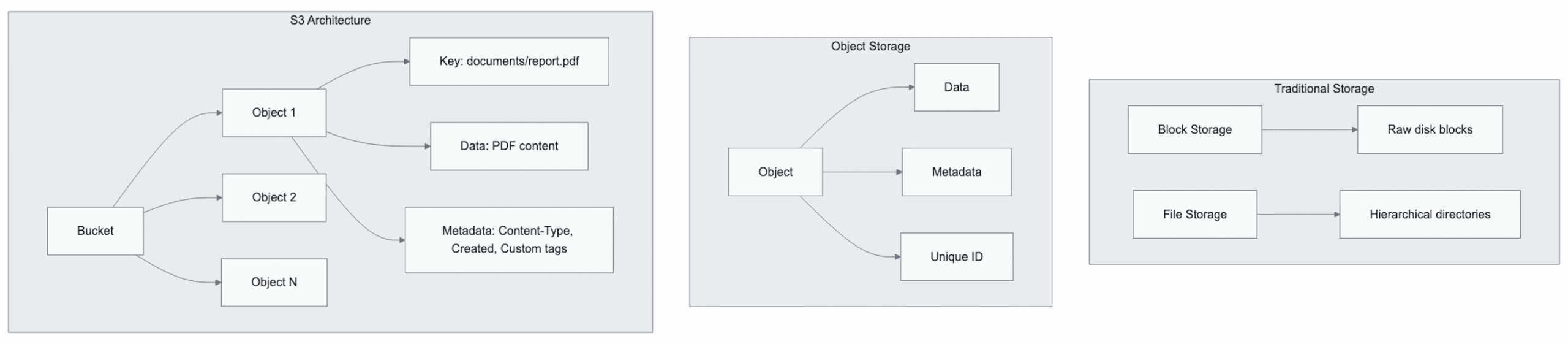
Why S3 Matters in Modern Architecture
S3’s significance extends beyond simple storage capabilities. It serves as a cornerstone for modern cloud-native architectures by providing:
- Microservices Integration: RESTful API design that seamlessly integrates with containerized applications
- Event-Driven Architecture Support: Native integration with AWS Lambda, SQS, and SNS for reactive system design
- Data Lake Foundation: Structured and unstructured data storage for analytics and machine learning workloads
- Content Delivery: Static asset hosting for web applications and CDN integration
Deep Dive: Core S3 Concepts and Architecture
Fundamental Components
Buckets: The Container Paradigm
S3 buckets serve as the fundamental organizational unit for object storage. Each bucket functions as a namespace container with specific characteristics:
Naming Requirements and Best Practices:
- Globally unique names across all AWS accounts and regions
- DNS-compliant naming (lowercase letters, numbers, hyphens)
- No underscores, periods, or uppercase letters
- Length between 3-63 characters
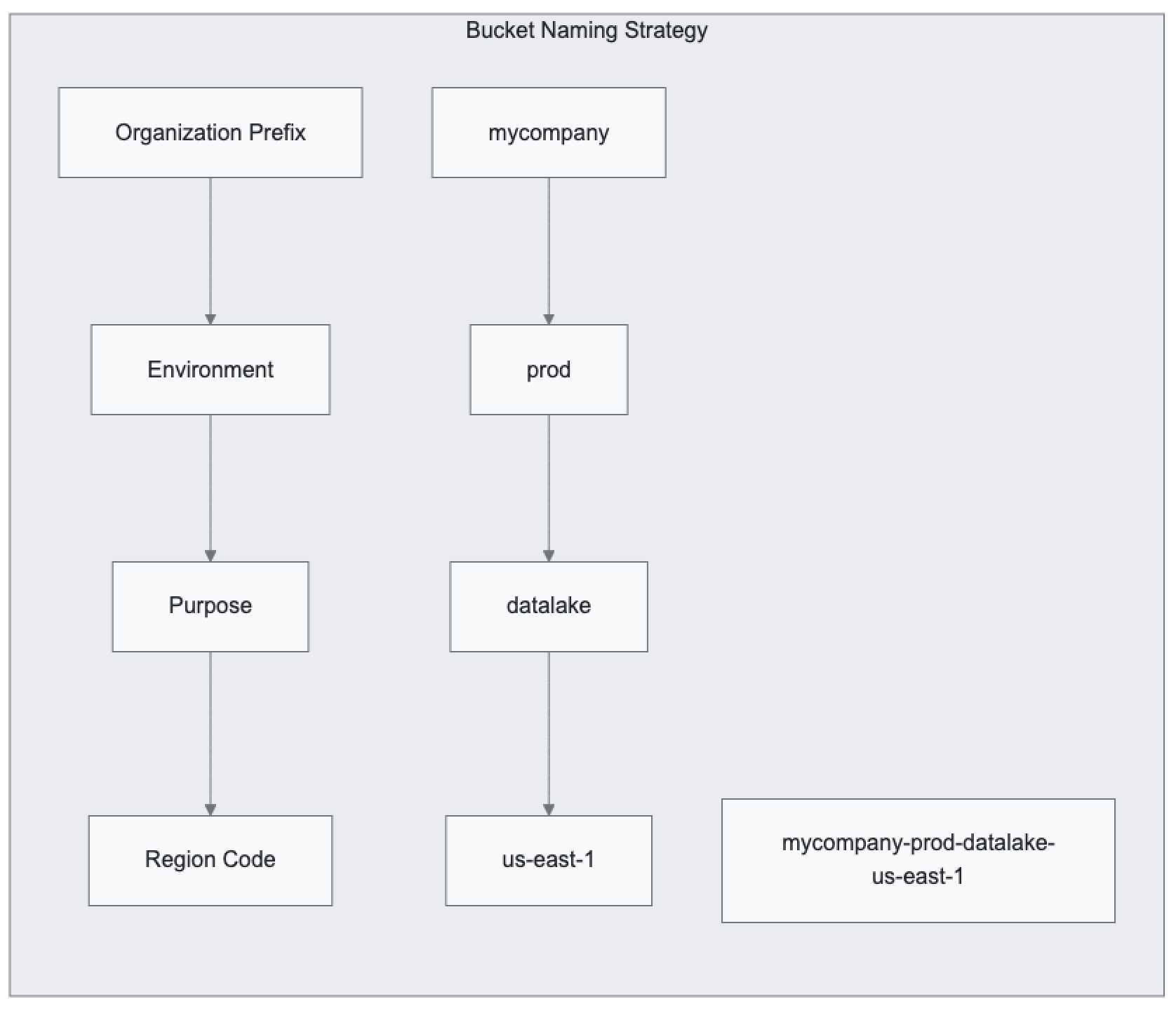
Regional Considerations:
Buckets exist within specific AWS regions, impacting:
- Latency: Proximity to users and applications
- Compliance: Data residency requirements
- Cost: Regional pricing variations
- Integration: Co-location with other AWS services
Objects: The Data Units
S3 objects represent individual files or data units with several key characteristics:
Object Key Structure:
The object key functions as a unique identifier within a bucket, supporting pseudo-hierarchical organization through delimiter conventions:
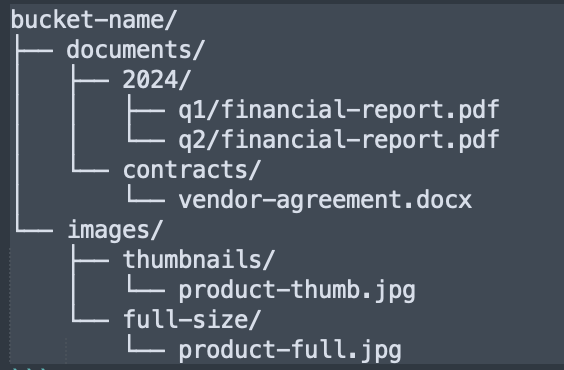
Size Limitations and Considerations:
- Maximum Object Size: 5 TB per individual object
- Single PUT Limit: 5 GB maximum
- Multipart Upload Requirement: Objects > 100 MB should use multipart uploads
- Minimum Billable Size: Varies by storage class (e.g., 128 KB for Glacier storage classes)
Storage Classes: Optimizing for Access Patterns
S3 provides multiple storage classes designed for different access patterns and cost optimization strategies:
Standard Storage Classes
S3 Standard:
- Use Case: Frequently accessed data with immediate access requirements
- Durability: 99.999999999% (11 9’s) across multiple Availability Zones
- Availability: 99.99% availability SLA
- Access Time: Milliseconds
- Ideal For: Active datasets, content distribution, analytics workloads
S3 Standard-Infrequent Access (S3 Standard-IA):
- Use Case: Data accessed monthly or less frequently
- Cost Structure: Lower storage cost, higher retrieval cost
- Minimum Storage Duration: 30 days
- Access Time: Milliseconds
- Ideal For: Backup data, disaster recovery, long-term archives with occasional access
Cold Storage Classes
S3 Glacier Instant Retrieval:
- Use Case: Archive data requiring millisecond access
- Minimum Storage Duration: 90 days
- Cost: ~68% less than S3 Standard
- Ideal For: Medical imaging, news media archives, compliance data
S3 Glacier Flexible Retrieval:
- Retrieval Options:
- Expedited: 1-5 minutes
- Standard: 3-5 hours
- Bulk: 5-12 hours
- Minimum Storage Duration: 90 days
- Ideal For: Annual audits, compliance archives, research data
S3 Glacier Deep Archive:
- Retrieval Time: 12-48 hours
- Cost: Lowest storage cost in S3
- Minimum Storage Duration: 180 days
- Ideal For: Long-term retention, regulatory compliance, digital preservation
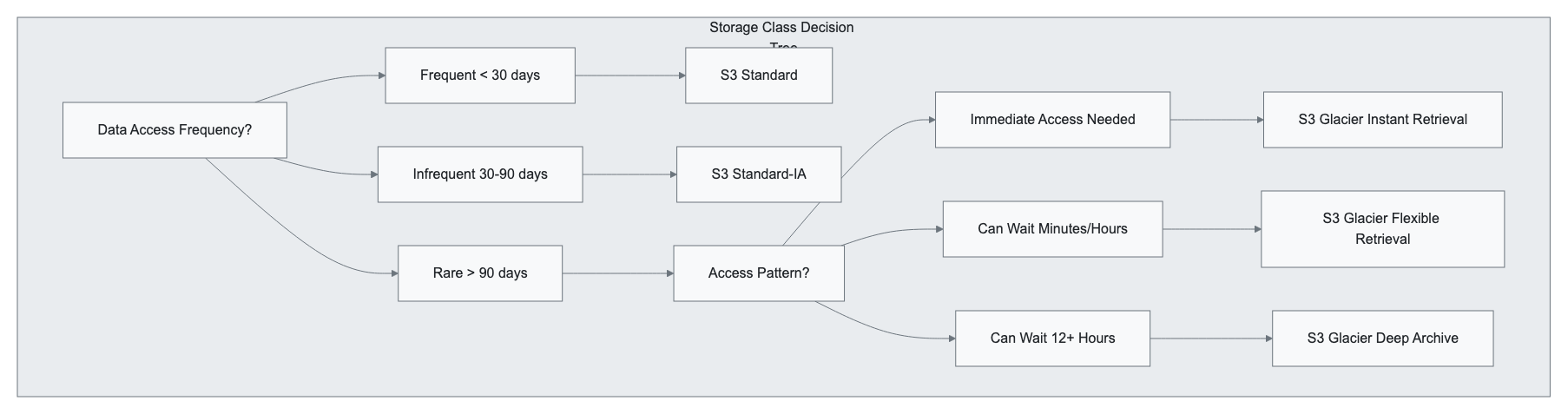
Intelligent Tiering
S3 Intelligent-Tiering:
- Automatic Optimization: Machine learning-driven storage class transitions
- Monitoring Fee: Small monthly fee per object
- Access Tiers:
- Frequent Access (similar to S3 Standard)
- Infrequent Access (similar to S3 Standard-IA)
- Archive Instant Access (similar to S3 Glacier Instant Retrieval)
- Archive Access (similar to S3 Glacier Flexible Retrieval)
- Deep Archive Access (similar to S3 Glacier Deep Archive)
Data Consistency and Durability
Consistency Model
S3 provides strong read-after-write consistency for all operations:
- PUT Operations: Immediately consistent for new objects
- UPDATE/DELETE Operations: Immediately consistent for existing objects
- LIST Operations: Eventually consistent (typically within seconds)
Durability Architecture
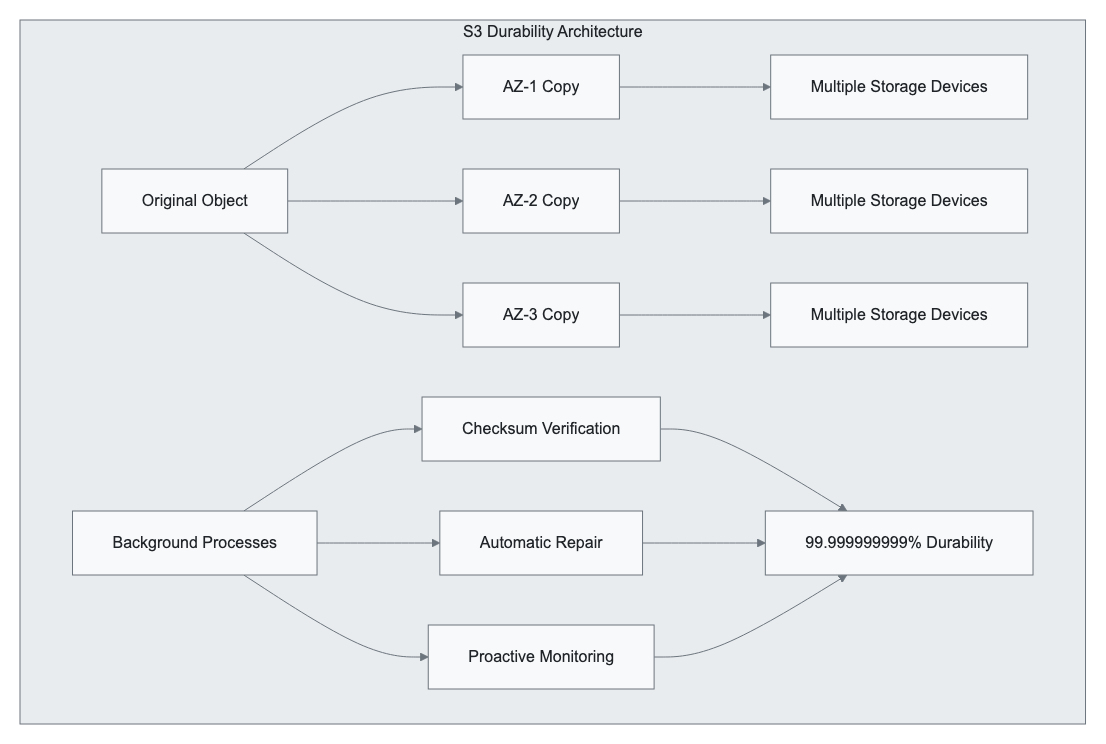
Durability Mechanisms:
- Geographic Distribution: Data replicated across multiple Availability Zones
- Checksum Verification: Continuous integrity monitoring
- Automatic Repair: Proactive replacement of degraded copies
- Versioning: Protection against accidental deletion or corruption
Advanced Features and Capabilities
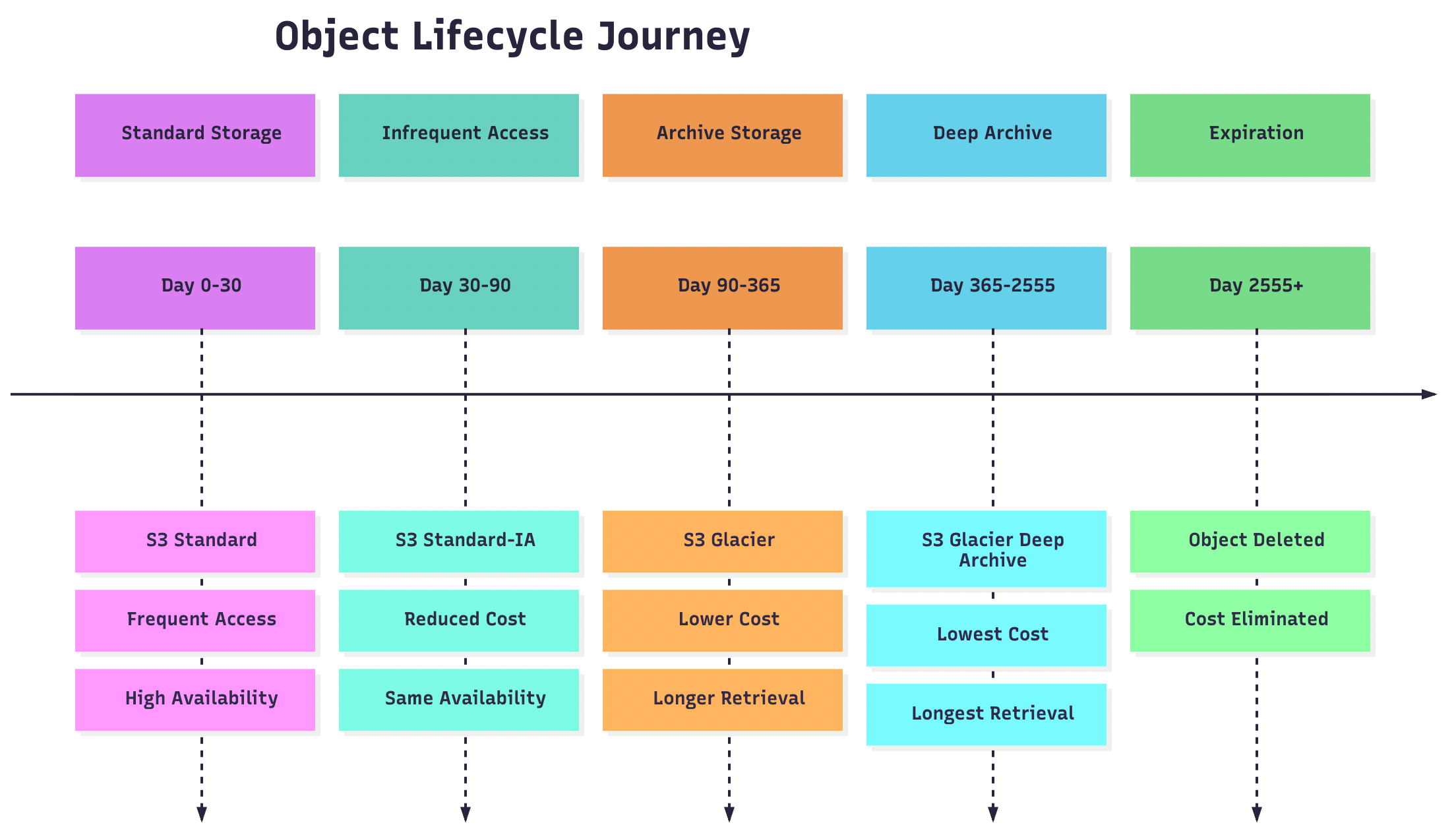
Lifecycle Management
S3 Lifecycle policies enable automated object management based on age, access patterns, or custom criteria:
{
"Rules": [
{
"ID": "CompanyDataLifecycle",
"Status": "Enabled",
"Transitions": [
{
"Days": 30,
"StorageClass": "STANDARD_IA"
},
{
"Days": 90,
"StorageClass": "GLACIER"
},
{
"Days": 365,
"StorageClass": "DEEP_ARCHIVE"
}
],
"Expiration": {
"Days": 2555
}
}
]
}
Versioning and Object Lock
S3 Versioning
Versioning provides protection against accidental deletion and modification:
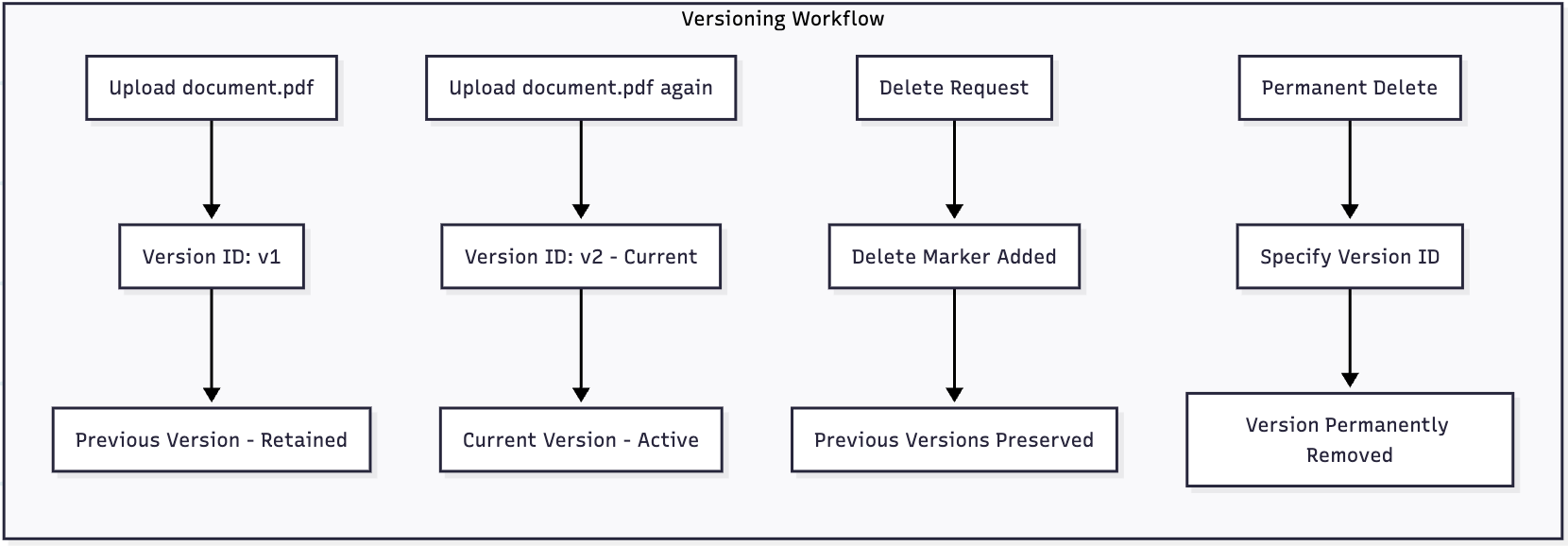
Versioning Best Practices:
- Enable versioning for critical data buckets
- Implement lifecycle rules for version cleanup
- Monitor storage costs for versioned objects
- Use MFA Delete for additional protection
S3 Object Lock
Object Lock provides WORM (Write Once, Read Many) compliance capabilities:
Lock Modes:
- Governance Mode: Users with specific permissions can modify retention
- Compliance Mode: No user can modify retention, including root user
Retention Types:
- Retention Period: Specific timeframe for object immutability
- Legal Hold: Indefinite hold until explicitly removed
Cross-Region Replication (CRR) and Same-Region Replication (SRR)
Replication enables automatic, asynchronous copying of objects across buckets:
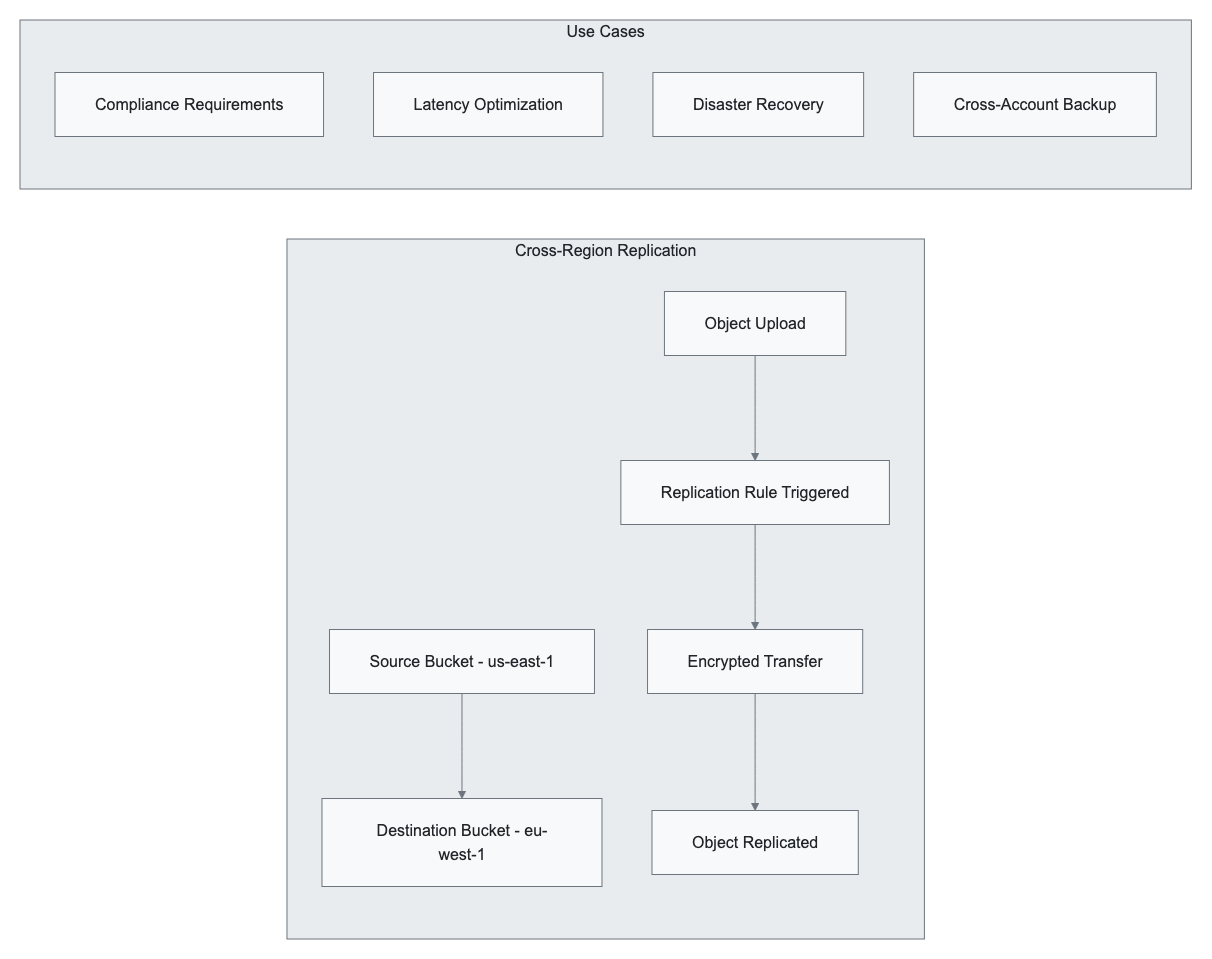
Replication Configuration Requirements:
- Source bucket versioning enabled
- Appropriate IAM permissions
- Destination bucket in different region (CRR) or same region (SRR)
- Optional: replica modifications, storage class changes
S3 Transfer Acceleration
Transfer Acceleration leverages Amazon CloudFront’s global edge network for optimized uploads:
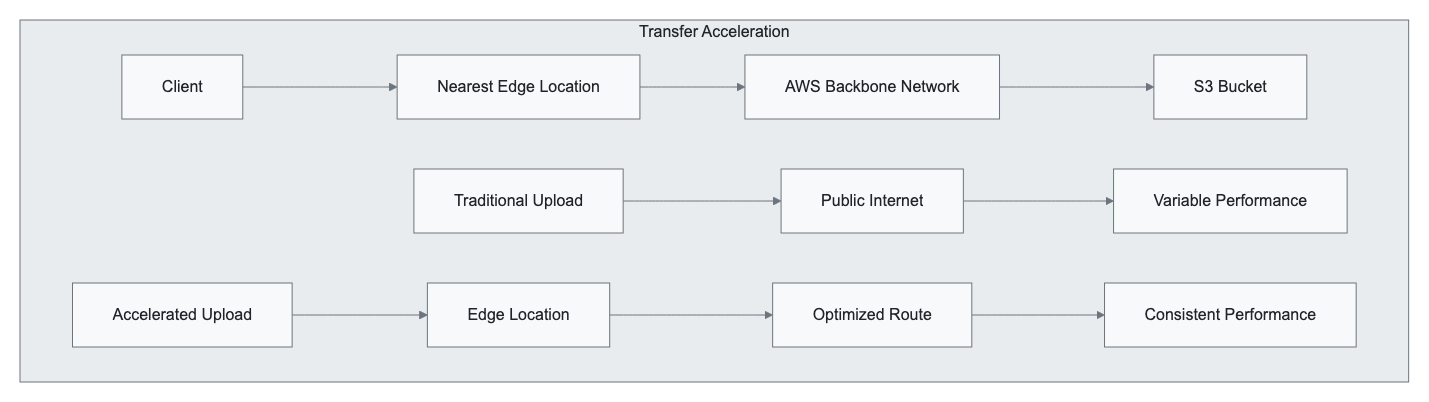
Performance Benefits:
- Up to 500% faster uploads for distant clients
- Consistent performance regardless of geographic location
- Automatic fallback to standard uploads if no improvement
Security and Access Control
Identity and Access Management (IAM) Integration
S3 security operates through multiple layers of access control mechanisms:
Bucket Policies
Bucket policies provide resource-based access control using JSON policy documents:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowSecureTransportOnly",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::company-sensitive-data",
"arn:aws:s3:::company-sensitive-data/*"
],
"Condition": {
"Bool": {
"aws:SecureTransport": "false"
}
}
},
{
"Sid": "AllowDepartmentAccess",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/FinanceDepartmentRole"
},
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": "arn:aws:s3:::company-sensitive-data/finance/*"
}
]
}
Access Control Lists (ACLs)
ACLs provide object-level and bucket-level permissions for basic access control:
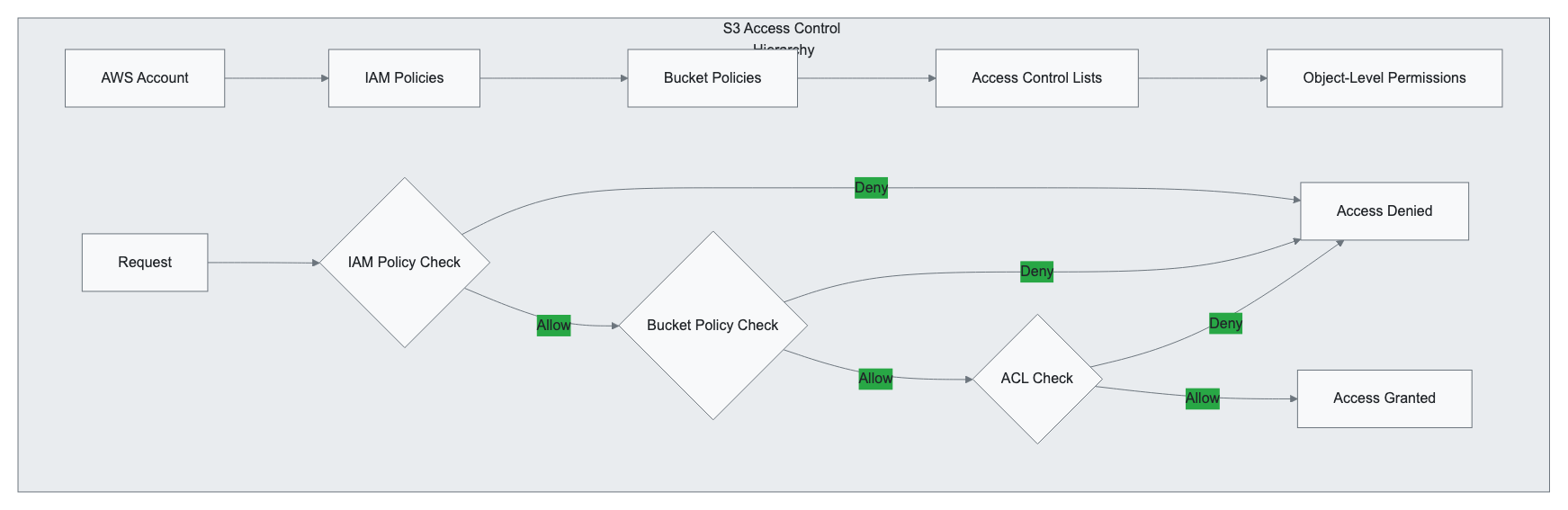
Encryption at Rest and in Transit
Server-Side Encryption (SSE)
SSE-S3 (S3-Managed Keys):
- AWS manages encryption keys automatically
- AES-256 encryption algorithm
- No additional configuration required
- Transparent to applications
SSE-KMS (AWS Key Management Service):
- Integration with AWS KMS for key management
- Audit trail for key usage
- Fine-grained access control
- Support for customer-managed keys
SSE-C (Customer-Provided Keys):
- Customer provides encryption keys
- AWS performs encryption/decryption operations
- Keys not stored by AWS
- Customer responsible for key management
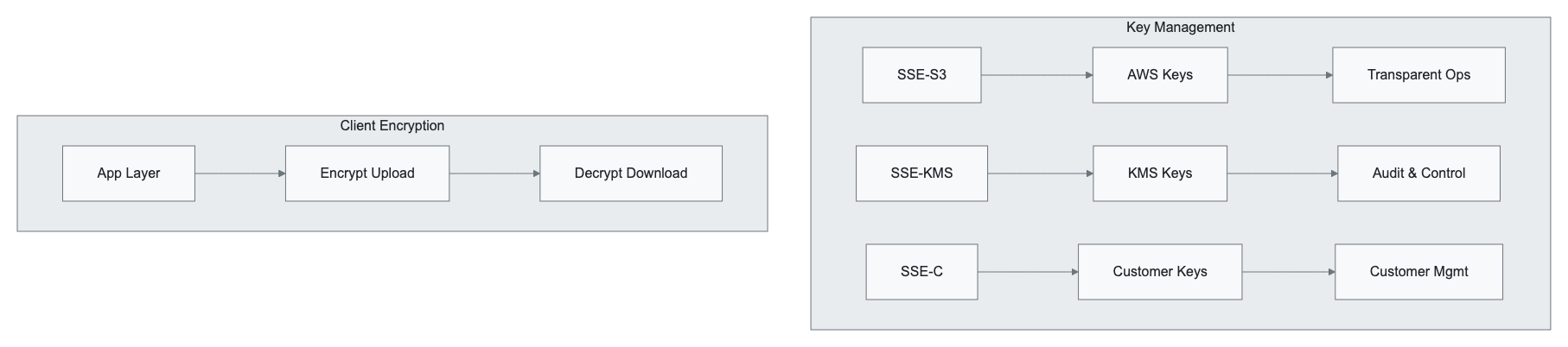
Encryption in Transit
All S3 communications support HTTPS/TLS encryption:
- API Calls: REST API over HTTPS
- Management Console: Web interface over HTTPS
- AWS CLI/SDKs: Configurable HTTPS enforcement
- Transfer Acceleration: Encrypted edge-to-S3 transfers
Access Logging and Monitoring
S3 Server Access Logs
Server access logs provide detailed records of requests made to S3 buckets:
bucket-name [06/Feb/2024:00:00:38 +0000] 198.51.100.1 arn:aws:sts::123456789012:assumed-role/application-role/i-1234567890abcdef0 3E57427F3EXAMPLE REST.GET.VERSIONING - "GET /bucket-name?versioning HTTP/1.1" 200 - 113 - 7 - "-" "S3Console/0.4" - 9vKBE6vMhrNiWHZmb2L0mXOcqPGzQOI5XLnCtZNPxev+Hf+7tpT6sxDwDty4LHBUOZJG96N1234EXAMPLE SigV4 ECDHE-RSA-AES128-GCM-SHA256 AuthHeader bucket-name.s3.amazonaws.com TLSv1.2
Log Fields Include:
- Bucket owner, bucket name, request time
- Remote IP address, requester identity
- Request ID, operation, key
- HTTP status, error code, response size
- Total time, turn-around time, referrer
AWS CloudTrail Integration
CloudTrail provides API-level logging for S3 management operations:
{
"eventVersion": "1.05",
"userIdentity": {
"type": "IAMUser",
"principalId": "AIDAI23HZ27SI6FQMGNQ2",
"arn": "arn:aws:iam::123456789012:user/backup-user",
"accountId": "123456789012",
"userName": "backup-user"
},
"eventTime": "2024-02-06T12:00:00Z",
"eventSource": "s3.amazonaws.com",
"eventName": "CreateBucket",
"sourceIPAddress": "198.51.100.1",
"resources": [
{
"ARN": "arn:aws:s3:::company-backup-bucket",
"accountId": "123456789012",
"type": "AWS::S3::Bucket"
}
]
}
Best Practices and Performance Optimization
Request Rate Performance
S3 automatically scales to handle high request rates, but optimal performance requires understanding request patterns:
Request Rate Guidelines
General Performance Characteristics:
- GET/HEAD/DELETE: 5,500 requests per second per prefix
- PUT/COPY/POST: 3,500 requests per second per prefix
- LIST: No specific limit, but pagination recommended
Prefix Optimization Strategies
Hot Spotting Avoidance:
# Poor prefix distribution (creates hot spots)
bucket/logs/2024-02-06-00-00-001.log
bucket/logs/2024-02-06-00-01-001.log
bucket/logs/2024-02-06-00-02-001.log
# Improved prefix distribution
bucket/01/logs/2024-02-06-00-00-001.log
bucket/02/logs/2024-02-06-00-01-001.log
bucket/03/logs/2024-02-06-00-02-001.log
# Optimal random distribution
bucket/a1f2c3d4/logs/2024-02-06-00-00-001.log
bucket/b2e3f4g5/logs/2024-02-06-00-01-001.log
bucket/c3f4g5h6/logs/2024-02-06-00-02-001.log
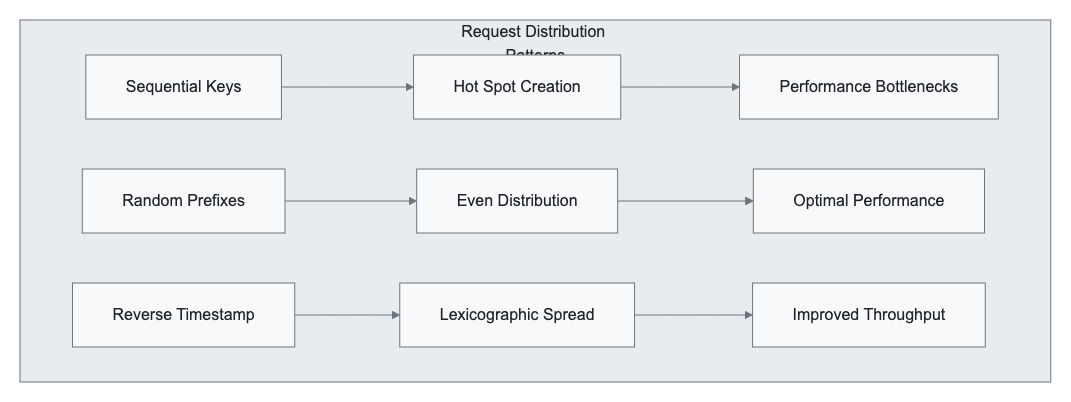
Multipart Upload Optimization
For objects larger than 100 MB, multipart uploads provide significant benefits:
Multipart Upload Benefits:
- Improved Throughput: Parallel upload of parts
- Quick Recovery: Resume failed uploads from specific parts
- Network Optimization: Better handling of unstable connections
Implementation Best Practices:
import boto3
from botocore.exceptions import NoCredentialsError
def optimized_multipart_upload(bucket_name, key, file_path, part_size=100*1024*1024):
"""
Optimized multipart upload with error handling and progress tracking
"""
s3_client = boto3.client('s3')
try:
# Initiate multipart upload
response = s3_client.create_multipart_upload(
Bucket=bucket_name,
Key=key,
ServerSideEncryption='AES256'
)
upload_id = response['UploadId']
parts = []
part_number = 1
with open(file_path, 'rb') as file:
while True:
data = file.read(part_size)
if not data:
break
# Upload part
part_response = s3_client.upload_part(
Bucket=bucket_name,
Key=key,
PartNumber=part_number,
UploadId=upload_id,
Body=data
)
parts.append({
'ETag': part_response['ETag'],
'PartNumber': part_number
})
part_number += 1
print(f"Uploaded part {part_number-1}")
# Complete multipart upload
s3_client.complete_multipart_upload(
Bucket=bucket_name,
Key=key,
UploadId=upload_id,
MultipartUpload={'Parts': parts}
)
print(f"Successfully uploaded {key}")
except Exception as e:
# Abort multipart upload on error
s3_client.abort_multipart_upload(
Bucket=bucket_name,
Key=key,
UploadId=upload_id
)
print(f"Upload failed: {e}")
raise
Cost Optimization Strategies
Storage Class Analysis
Regular analysis of access patterns enables optimal storage class selection:


Request Cost Management
Understanding request pricing helps optimize application patterns:
Request Pricing Considerations:
- PUT, COPY, POST, LIST: Higher cost per request
- GET, SELECT: Lower cost per request
- DELETE, CANCEL: No charge
- Lifecycle Transitions: Charged per object
Optimization Techniques:
- Batch operations where possible
- Implement client-side caching
- Use CloudFront for frequently accessed content
- Optimize LIST operations with pagination
Monitoring and Alerting
CloudWatch Metrics
S3 provides comprehensive CloudWatch metrics for monitoring:
Storage Metrics:
BucketSizeBytes: Total bucket storage usageNumberOfObjects: Object count per bucketAllRequests: Total request countGetRequests,PutRequests: Specific operation counts
Custom Alerting Example:
{
"AlarmName": "S3-HighRequestRate",
"ComparisonOperator": "GreaterThanThreshold",
"EvaluationPeriods": 2,
"MetricName": "AllRequests",
"Namespace": "AWS/S3",
"Period": 300,
"Statistic": "Sum",
"Threshold": 10000.0,
"ActionsEnabled": true,
"AlarmActions": [
"arn:aws:sns:us-east-1:123456789012:s3-alerts"
],
"AlarmDescription": "Alert when S3 request rate exceeds threshold"
}
Real-World Use Cases and Implementation Scenarios
Data Lake Architecture
S3 serves as the foundational storage layer for modern data lakes, supporting structured and unstructured data analytics:

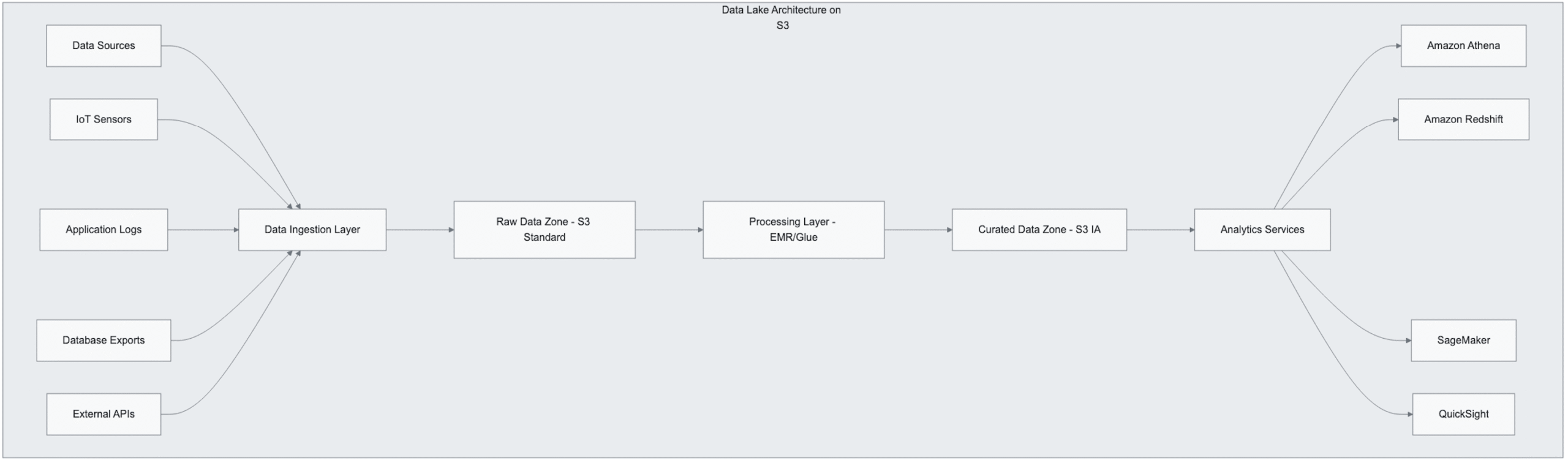
Implementation Considerations:
- Partitioning Strategy: Organize data by date, region, or business unit
- File Format Optimization: Use columnar formats (Parquet, ORC) for analytics
- Compression: Enable compression to reduce storage costs and improve query performance
- Access Patterns: Design folder structure to support query patterns
Content Distribution and Static Website Hosting
S3 integrates seamlessly with CloudFront for global content distribution:
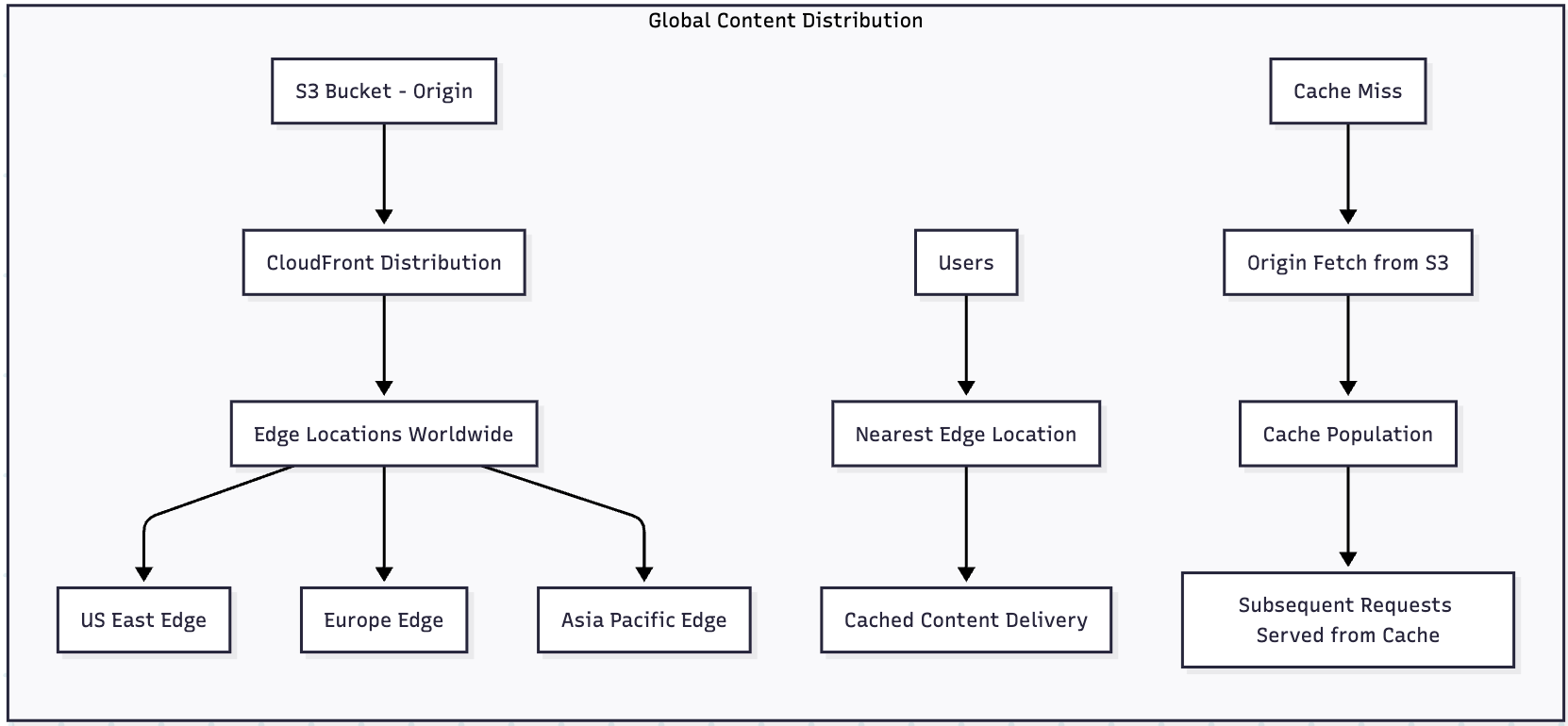
Static Website Configuration:
{
"IndexDocument": {
"Suffix": "index.html"
},
"ErrorDocument": {
"Key": "404.html"
},
"RedirectAllRequestsTo": {
"HostName": "www.example.com",
"Protocol": "https"
}
}
Backup and Disaster Recovery
S3’s durability and cross-region replication capabilities make it ideal for enterprise backup strategies:
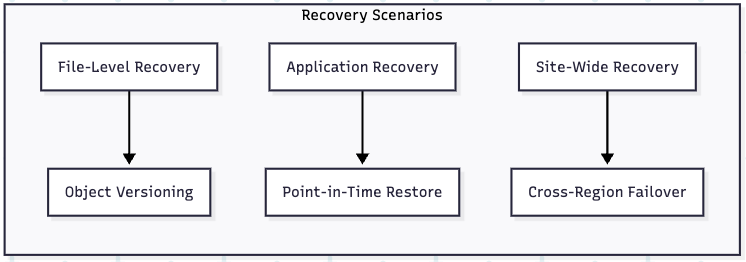
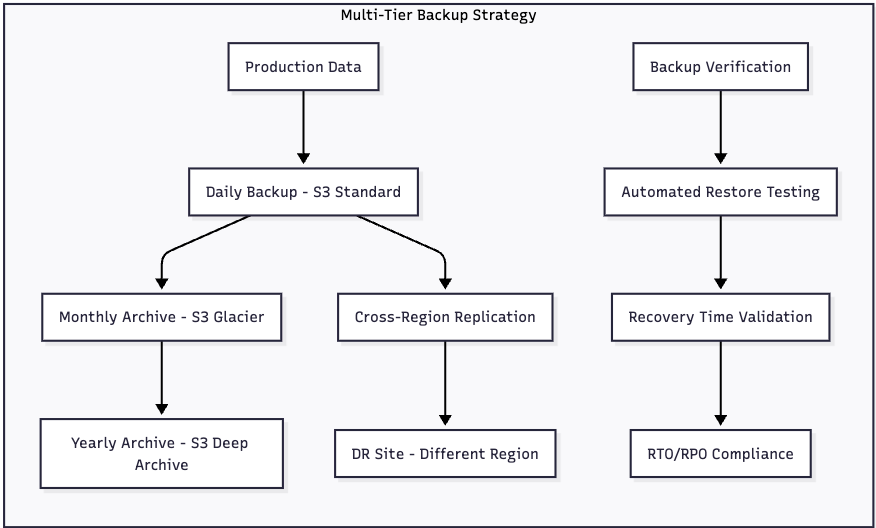
Application Integration Patterns
Event-Driven Processing
S3 event notifications enable reactive architecture patterns:
import json
import boto3
def lambda_handler(event, context):
"""
Process S3 events for automated data pipeline
"""
s3_client = boto3.client('s3')
for record in event['Records']:
# Extract event information
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
event_name = record['eventName']
if event_name.startswith('ObjectCreated'):
# Trigger data processing pipeline
process_new_file(bucket, key)
elif event_name.startswith('ObjectRemoved'):
# Clean up associated metadata
cleanup_metadata(bucket, key)
return {
'statusCode': 200,
'body': json.dumps('Event processed successfully')
}
def process_new_file(bucket, key):
"""
Process newly uploaded files
"""
# Validate file format
if key.endswith('.csv'):
trigger_etl_pipeline(bucket, key)
elif key.endswith('.json'):
validate_json_schema(bucket, key)
def trigger_etl_pipeline(bucket, key):
"""
Start ETL process for CSV files
"""
# Implementation for ETL triggering
pass
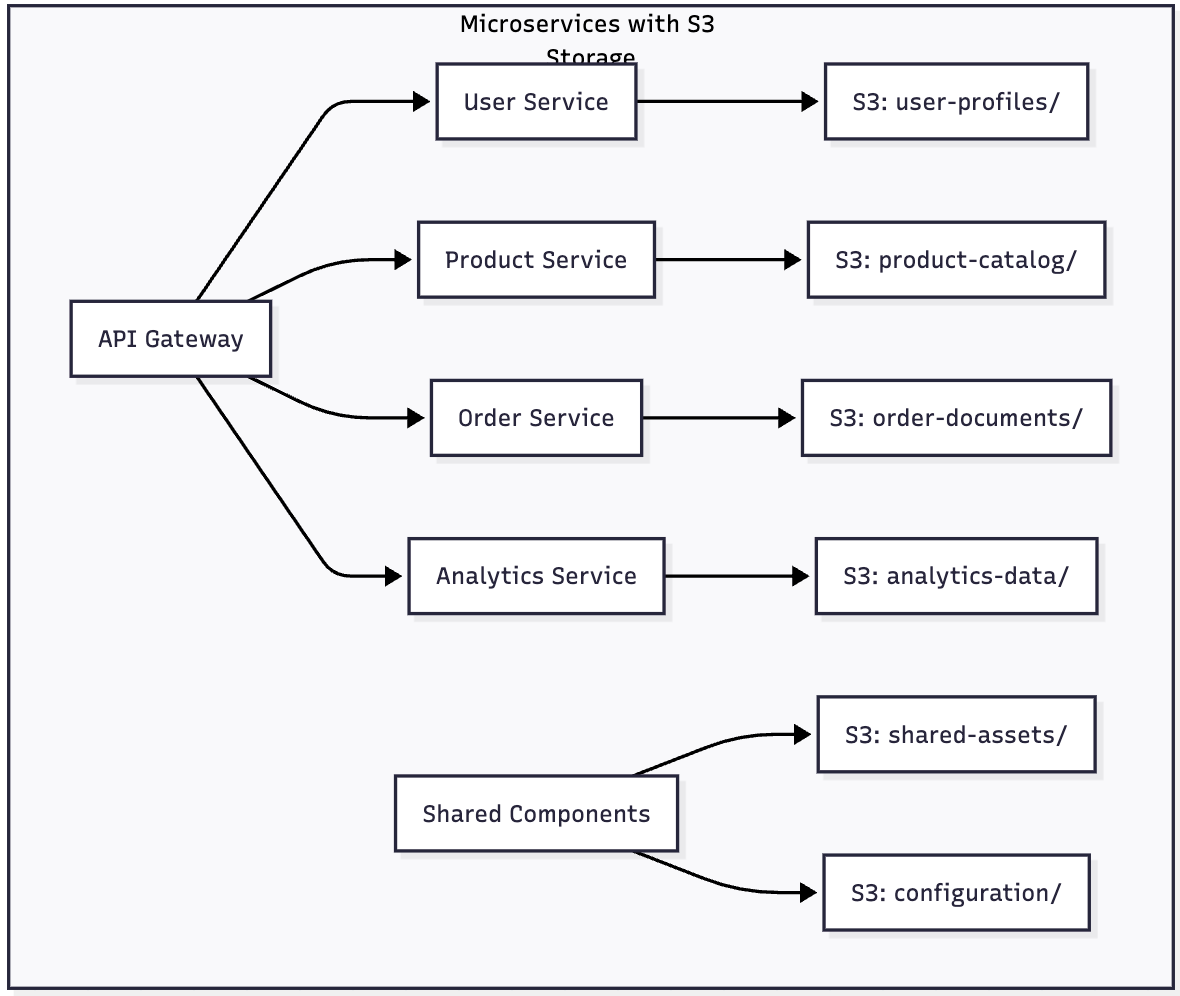
Microservices Data Storage
S3 provides decentralized storage for microservices architectures:
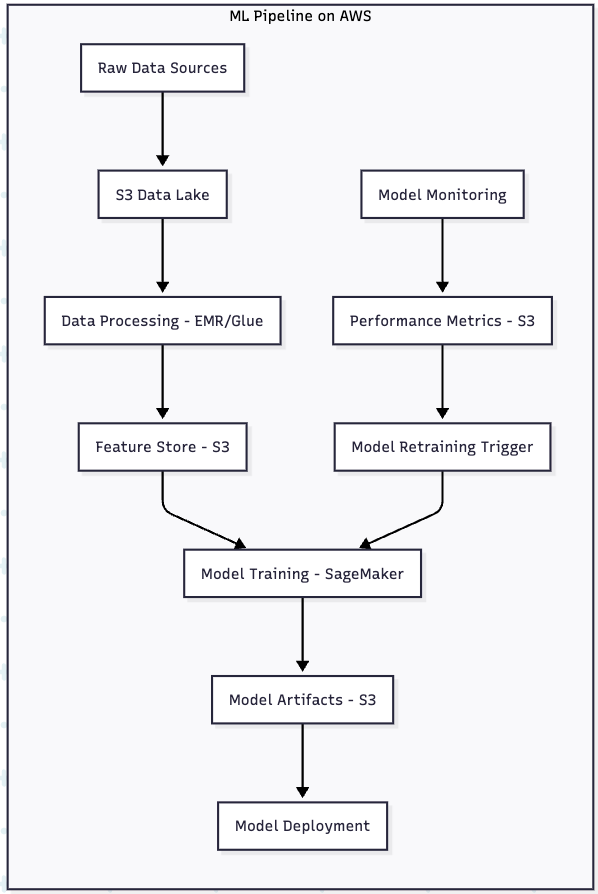
Machine Learning and AI Workloads
S3 serves as the primary data repository for machine learning pipelines:

Advanced Security Patterns
Zero Trust Architecture
Implementing zero trust principles with S3 requires comprehensive security controls:
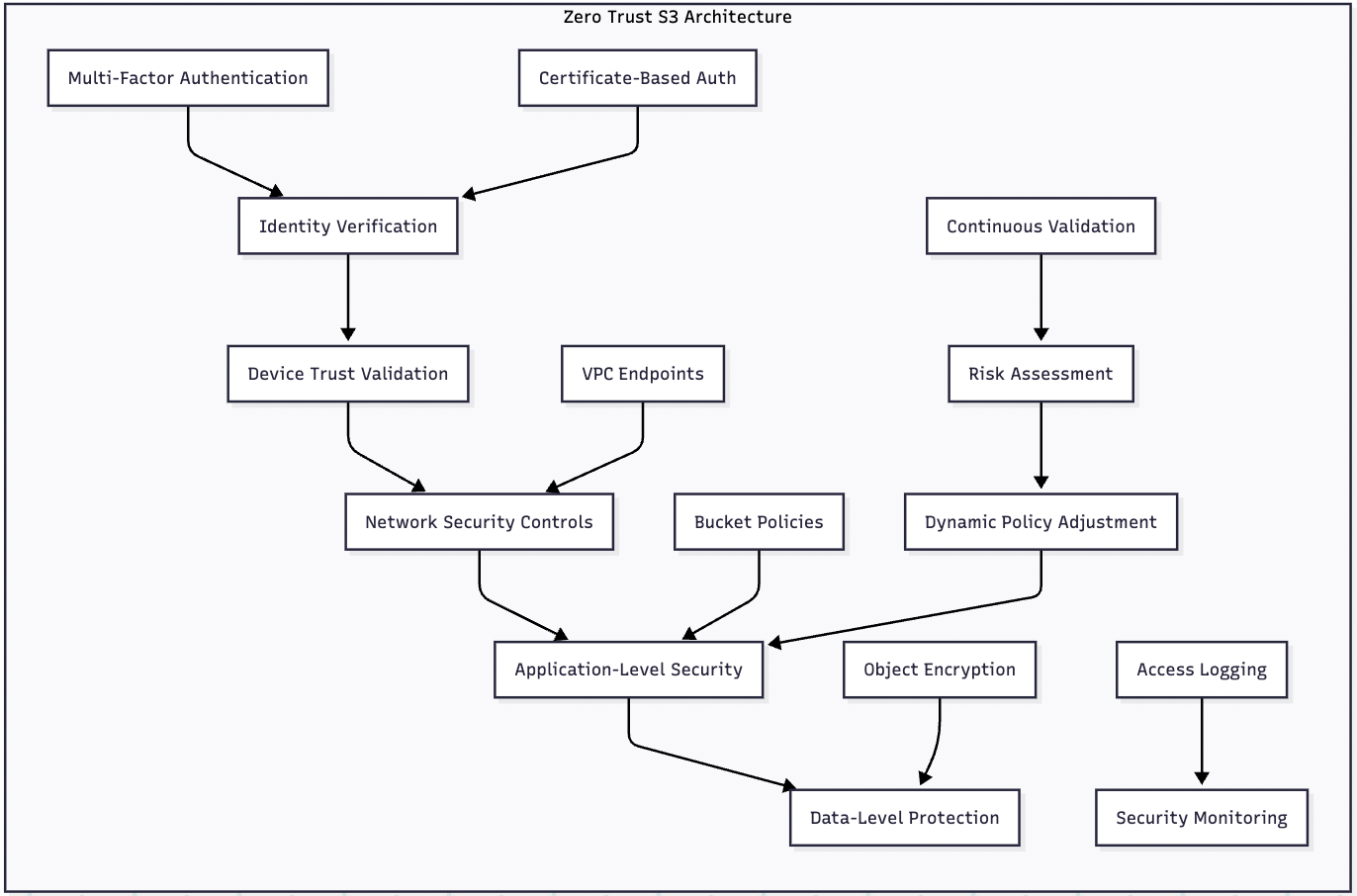
Implementation Components:
- VPC Endpoints: Private connectivity to S3 without an internet gateway
- Bucket Policies: Condition-based access control
- IAM Roles: Temporary credentials with limited scope
- CloudTrail: Comprehensive audit logging
- AWS Config: Configuration compliance monitoring
Compliance and Governance
S3 supports various compliance frameworks through built-in features:
GDPR Compliance Pattern:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "GDPRDataProcessing",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:role/GDPRProcessorRole"
},
"Action": [
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::gdpr-personal-data/*",
"Condition": {
"StringEquals": {
"s3:ExistingObjectTag/DataClassification": "PersonalData"
},
"DateGreaterThan": {
"aws:RequestedRegion": "eu-west-1"
}
}
}
]
}
Future Outlook and Emerging Trends
Integration with AI/ML Services
S3 continues evolving as the foundation for AI and machine learning workloads:
Emerging Capabilities:
- S3 Object Lambda: Real-time data transformation during retrieval
- Amazon Textract Integration: Automatic document processing
- Amazon Rekognition: Image and video analysis at scale
- Amazon Comprehend: Natural language processing for stored documents
Sustainability and Green Cloud Practices
AWS’s commitment to carbon neutrality by 2040 influences S3 development:
Sustainability Features:
- Intelligent Tiering: Automatic optimization reduces storage resource consumption
- Lifecycle Management: Automated deletion reduces unnecessary storage
- Regional Optimization: Data placement near processing reduces network traffic
- Compression Integration: Native compression support reduces storage requirements
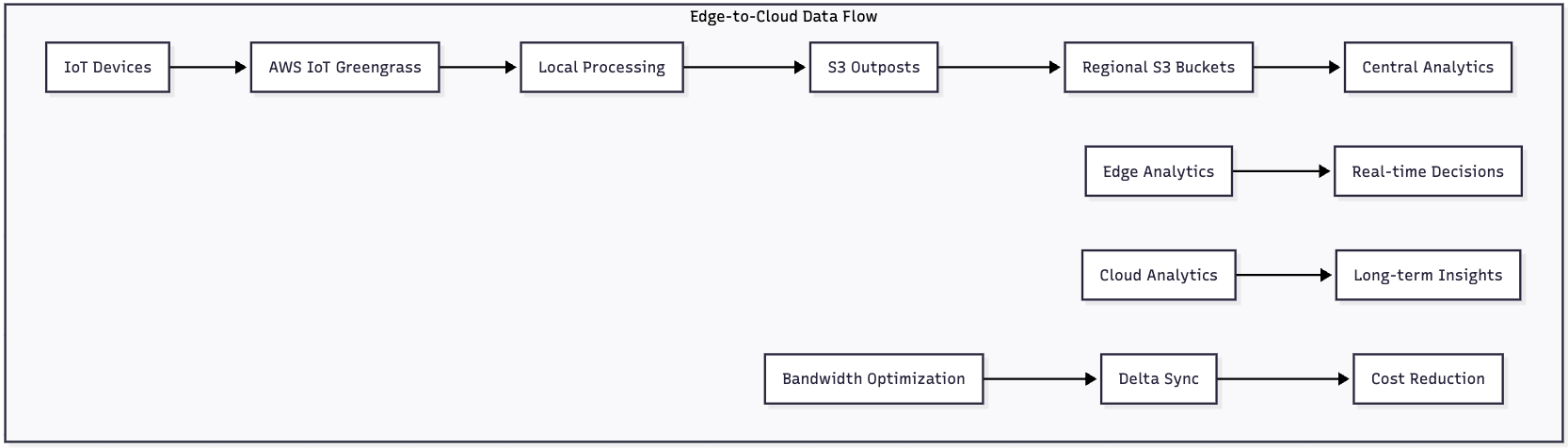
Edge Computing Integration
S3 integration with edge computing expands data processing capabilities:
Conclusion
Amazon S3 has evolved far beyond simple object storage to become a comprehensive data management platform that enables modern cloud-native architectures. Its combination of durability, scalability, security, and cost-effectiveness makes it an indispensable component of enterprise cloud strategies.
Key Takeaways
Technical Excellence:
- S3’s 99.999999999% durability provides enterprise-grade data protection
- Multiple storage classes enable cost optimization for diverse access patterns
- Strong consistency model simplifies application development
- Comprehensive security features support zero-trust architectures
Operational Benefits:
- Virtually unlimited scalability eliminates capacity planning concerns
- Pay-as-you-use pricing model aligns costs with actual usage
- Global infrastructure supports worldwide application deployment
- Rich ecosystem integration accelerates development velocity
Strategic Advantages:
- A foundation for data lake architectures enables advanced analytics
- Event-driven capabilities support modern reactive systems
- Machine learning integration accelerates AI initiatives
- Compliance features address regulatory requirements
Action Items for Implementation
Immediate Steps:
- Assess Current Storage: Inventory existing storage systems and access patterns
- Define Strategy: Establish storage class selection criteria and lifecycle policies
- Security Review: Implement encryption, access controls, and monitoring
- Cost Optimization: Configure lifecycle management and intelligent tiering
Medium-term Goals:
- Integration Planning: Design S3 integration with existing applications
- Disaster Recovery: Implement cross-region replication for critical data
- Performance Optimization: Configure request rate optimization and caching
- Monitoring Implementation: Deploy comprehensive logging and alerting
Long-term Vision:
- Data Lake Development: Build analytics capabilities on S3 foundation
- AI/ML Integration: Leverage S3 for machine learning pipelines
- Edge Computing: Extend capabilities with S3 Outposts and edge services
- Sustainability: Implement green cloud practices for environmental responsibility
Auto Amazon Links: No products found.