


What you’ll learn
- What CQRS is and why it exists
- How to implement CQRS on AWS using standard serverless components
- How the write model and read model stay in sync (and what “eventual consistency” means in practice)
- Key production considerations: failures, retries, idempotency, monitoring, and security
Video discussion on YouTube – https://youtu.be/2lFW5H3ZzLA
The problem CQRS solves
In many systems, we try to make one database schema do everything:
- Handle writes with strong correctness rules (validation, constraints, transactions)
- Serve complex reads (search, filtering, aggregations, “feed” style queries)
As the system grows, that single model starts to hurt:
- Writes become complicated because the schema is optimized for read queries
- Reads become slow because the schema is optimized for updates and integrity
- Every new feature adds more indexes, more joins, more hot partitions, or more caching hacks
CQRS (Command Query Responsibility Segregation) is a pattern that says:
- Commands (writes) and Queries (reads) have different jobs
- So it’s often beneficial to give them different models, and sometimes different datastores
CQRS in one sentence
CQRS separates the write path (commands) from the read path (queries) and keeps a read-optimized model in sync with the write model via asynchronous events.
In this AWS version:
- Write path: API Gateway → Lambda → DynamoDB (write model)
- Read path: DynamoDB Streams → Lambda → Amazon OpenSearch Service (read model)
Note: In many older diagrams, you’ll see “Elasticsearch”—on AWS, the managed service is now Amazon OpenSearch Service.
High-level architecture (AWS components)
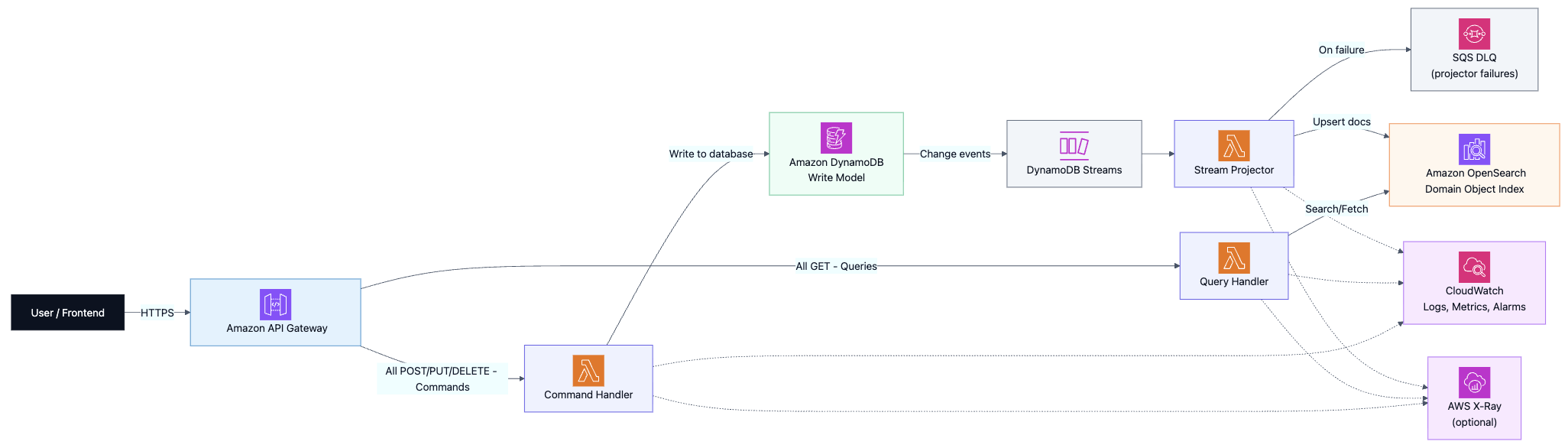
What each component is responsible for
- API Gateway: public HTTP endpoints (rate limiting, auth integration, request validation if desired)
- Command Lambda: validates commands and writes the source of truth to DynamoDB
- DynamoDB (write model): authoritative state; optimized for writes and correctness rules
- DynamoDB Streams: reliable change feed whenever DynamoDB items change
- Projector Lambda: transforms DynamoDB changes into read-optimized documents
- OpenSearch (read model): optimized for search, filtering, sorting, aggregations, “feed” queries
- Query Lambda: serves fast queries from OpenSearch (and can enforce authorization)
- DLQ (SQS): catches failed projections so you don’t lose updates silently
- CloudWatch/X-Ray: logs, metrics, alarms, tracing across the flow
A concrete example to explain it (simple “Orders” domain)
Imagine an e-commerce service.
Commands (write intent)
- CreateOrder(orderId, customerId, items…)
- ConfirmPayment(orderId, paymentId)
- CancelOrder(orderId, reason)
These commands must enforce business rules:
- Don’t confirm payment twice
- Don’t cancel a shipped order
- Validate inventory or price snapshots
Queries (read intent)
- “Show me all orders for a customer, newest first”
- “Search orders by product name”
- “Give me daily revenue totals”
Those are typically easier and faster in a search/analytics-friendly store like OpenSearch.
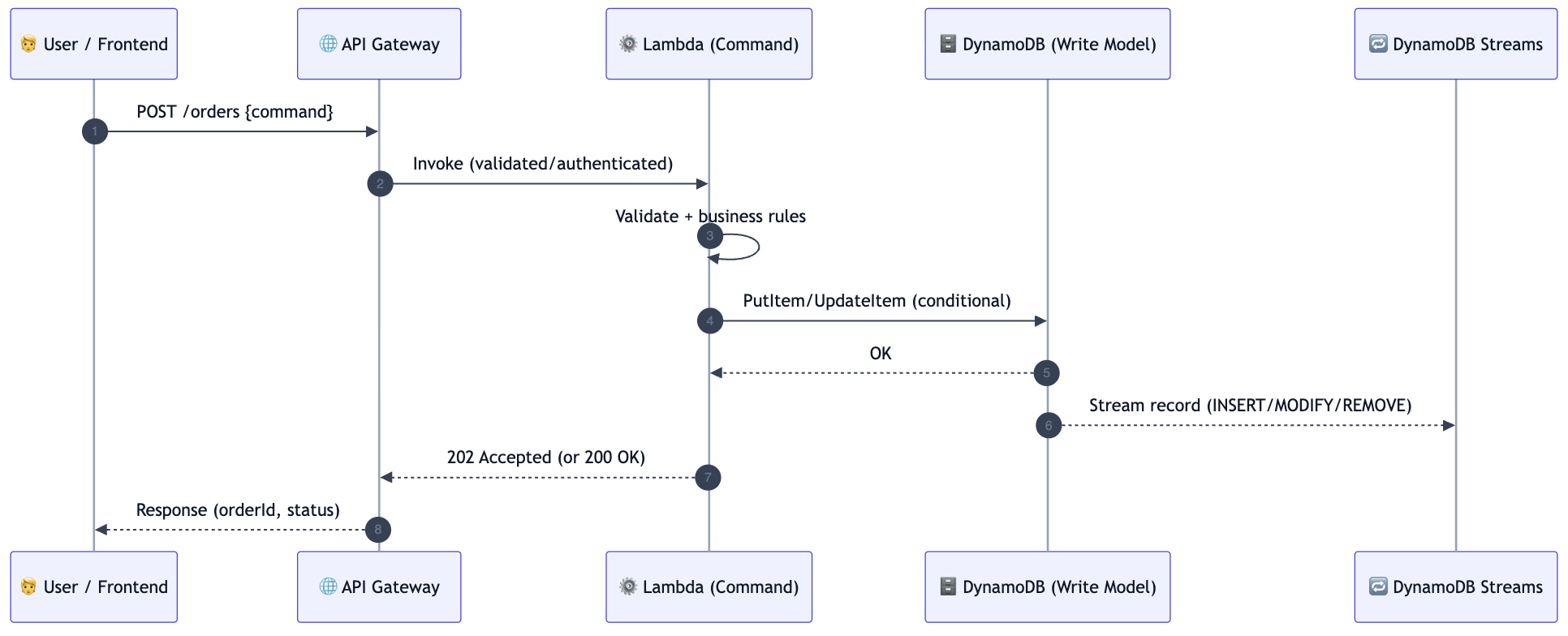
The write path (Command side) — how data is written
The command side focuses on correctness and business rules.
Practical AWS flow:
- Client calls POST /orders (or PUT /orders/{id})
- API Gateway forwards to Command Lambda
- Lambda validates the request and applies business logic
- Lambda writes to DynamoDB (often with conditional writes for correctness)
- DynamoDB emits a change record to DynamoDB Streams
Command side sequence (what happens, in order)
The read path (Query side) — how data is read fast
The query side focuses on speed and flexible access patterns.
Practical AWS flow:
- DynamoDB Streams triggers the Projector Lambda
- Projector transforms the change into one or more read documents
- Projector writes/upserts into OpenSearch
- Client calls GET /orders?customerId=…
- Query Lambda reads from OpenSearch and returns results quickly
Projection + query sequence (and where eventual consistency appears)
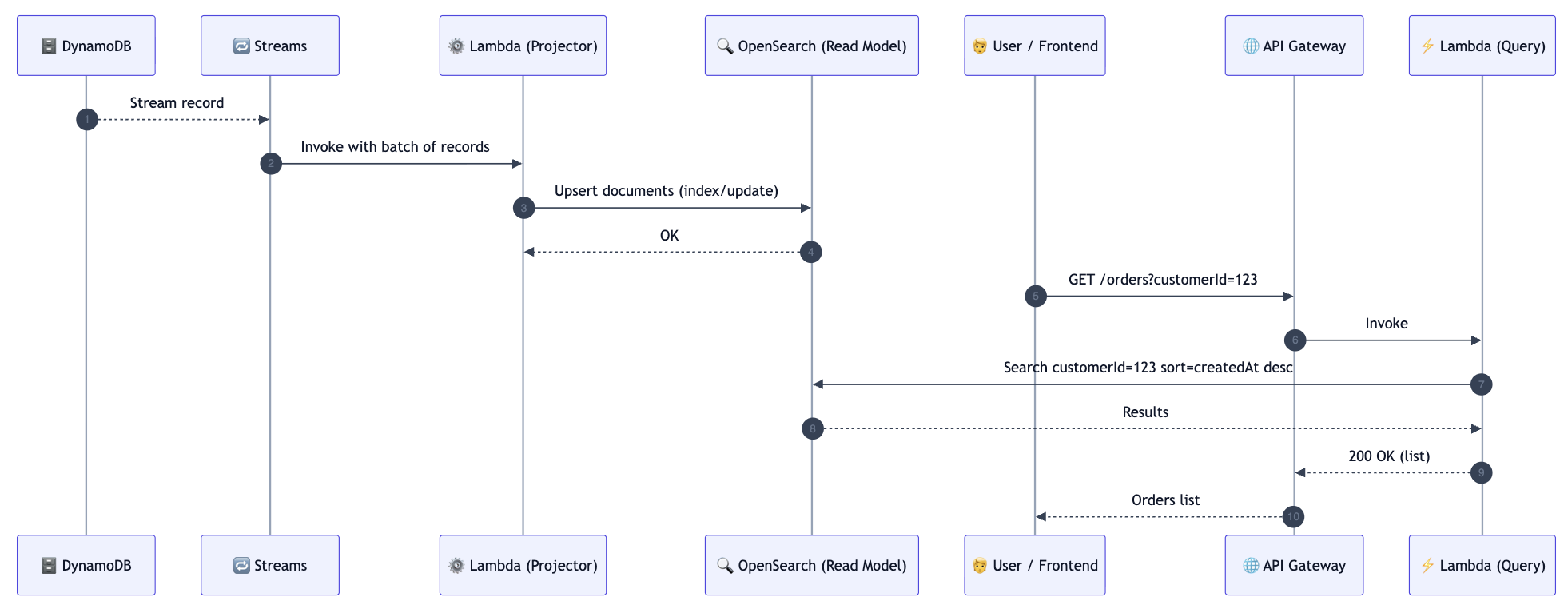
What “eventual consistency” means here
Immediately after a command succeeds, the read model might still be catching up for a short time (milliseconds to seconds, depending on load, retries, and indexing).
For most product experiences, that’s fine. When it’s not fine, you can:
- Read-your-own-write on the command side (return the computed state from DynamoDB for that request)
- Show UI states like “Processing…” until the query model reflects the change
- Provide an endpoint that reads directly from the write model for critical screens
Why DynamoDB + Streams + OpenSearch is a standard CQRS combo
- DynamoDB is great for high-throughput writes, conditional updates, and predictable scaling
- Streams gives you a durable change feed without running your own Kafka cluster
- OpenSearch excels at search, filters, faceted navigation, text queries, and aggregations
This combo is handy for:
- Search-heavy apps (marketplaces, content platforms)
- Event timelines and activity feeds
- Admin dashboards with flexible filtering
Production checklist (the stuff that makes CQRS work reliably)
1) Idempotency on the projector
Streams can deliver retries; OpenSearch operations should be idempotent.
- Use deterministic document IDs (for example, orderId)
- For deletes, handle REMOVE events cleanly
2) Error handling with DLQ + replay strategy
If the projection fails, you need a recovery plan:
- Configure Lambda destinations or an SQS DLQ
- Log enough context to reprocess
- Keep a “rebuild read model” job in your back pocket (re-scan DynamoDB and re-index)
3) Ordering and concurrency assumptions
Streams preserve ordering per partition key, but at scale you still need to design for:
- Out-of-order updates across different keys
- Parallel batches in Lambda
4) Data modeling: keep the read model purpose-built
Your OpenSearch document can be denormalized:
- Include customer name, totals, status, timestamps, and searchable fields
- Precompute what you need for query performance (within reason)
5) Observability
Minimum baseline:
- CloudWatch alarms on projector errors, DLQ depth, and OpenSearch write failures
- A dashboard for stream iterator age/lag (how far behind projections are)
6) Security
Good defaults:
- IAM least privilege between Lambdas, DynamoDB, and OpenSearch
- KMS encryption for DynamoDB and OpenSearch
- If OpenSearch is VPC-only, ensure Lambdas run in VPC with correct networking
- Use Cognito (or a JWT authorizer) for user-facing auth
When CQRS is a great fit (and when it’s overkill)
Great fit:
- Read patterns are complex and change frequently
- You need search/analytics queries without impacting writes
- You can tolerate brief eventual consistency on the read side
Overkill:
- A single database model can handle your load and query needs
- Your domain requires strict read-after-write consistency everywhere
- Your team is small, and operational simplicity is the top priority
Optional upgrades (nice to mention)
- Replace Streams→Projector with EventBridge or Kinesis for more complex fan-out
- Use Aurora/RDS as the write model when transactions/joins are required
- Add Step Functions when commands become multi-step workflows
- Split into microservices, where each service owns its own command and query models
Auto Amazon Links: No products found.